

最近は、音声認識の進歩が凄まじく、”音声”をテキスト化できるアプリが多数あります。
しかし、mp3等の”音声ファイル”をテキスト化できる無料のアプリやサービスは、現状あまりみかけません。
そのため、スマホなどでmp3ファイルを再生し、別のスマホの音声認識アプリで音声をテキスト化したりして試していました。
AIが音声ファイルをテキスト化してくれる
Watsonって聞いたことがある方が多いと思いますが、IBMが開発した質問応答システム・意思決定支援システムとのことです。
その”Watson”がサポートしている Speech to Text Demo サービスでは、音声ファイルから無料でテキスト化を行うことができます。
Speech to Text Demo について
このシステムは、デモンストレーションを目的としていますと明言していますが、それはEUのデータ保護規則の要件を満たしていない可能性を考慮してのことのようです。
つまり、デモ以外で利用するなというより、デモという扱いにしておかないと、問題がおきたら困るということでしょう。
あくまでも、利用する場合は個人の判断でお願いします。
機能や特徴について
- 音声認識機能を使用して、アラビア語、英語、スペイン語、フランス語、ブラジルポルトガル語、日本語、韓国語、ドイツ語、北京語の音声をテキストに変換できます。
- 音声ファイル対応フォーマットは、mp3、mpeg、wav、flac、opusのみテキスト化ができます。
- 良い出力結果を得るには、「Voice Model」をブロードバンドモデル「Japanese broadband model(16KHz)」にして、行ってください。
- 話者が複数いる場合は、「Detect multiple speakers」をチェックしてからテキスト化してください。
サンプルで試してみる
まずは、サンプルが用意されていますので、どのようにテキスト化されるのかを見てみます。
サンプルの出力結果

このように対話でのやり取りの音声をテキスト化しています。
やり取りですから2人いるわけで、出力結果だけ見るとわからないでしょうが、テキスト化の途中で「Speaker0」「Speaker1」を判別しながら、考えているような様子が見て取れます。
音声ファイルをテキスト化してみる
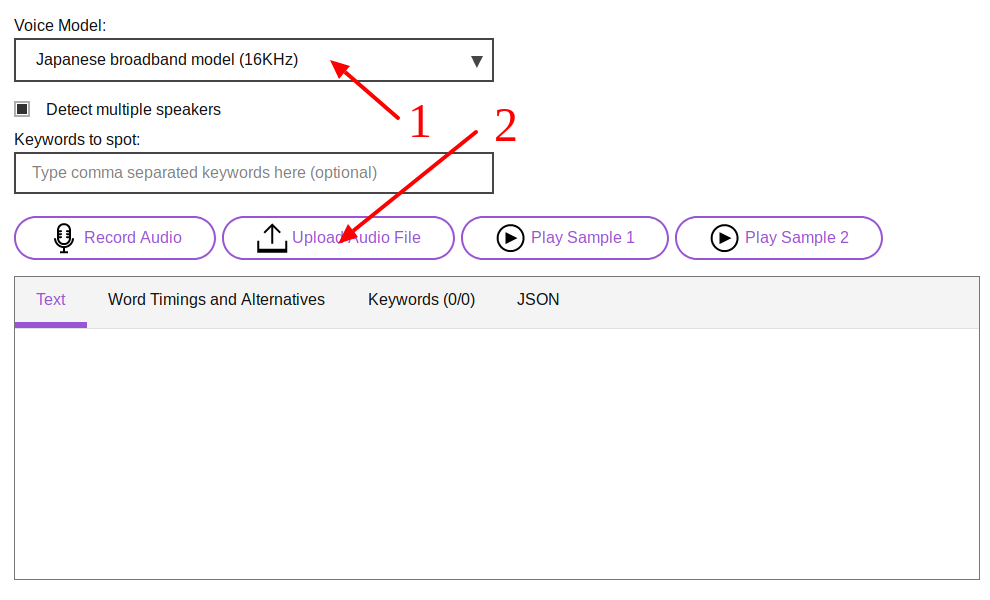
- 音声ファイルをテキスト化する場合は、矢印「1」の「Voice Model」を「Japanese broadband model(16KHz)」に設定します。
- 矢印「2」の「Upload Audio File」をクリックして、mp3などの音声ファイルを選択し、アップロードします。
- あとは、タダ待つだけです。
アップロードされた音声ファイルを再生しながら、テキスト化を行うので、ミュートにして音がしないようにしてしまうと、テキスト化できませんでした。
そして、再生しながらということで、再生時間だけテキスト化の処理時間がかかります。
また、朗読などの聞かせるために録音したような音声ファイルは良いのですが、ラジオの録音(雑談で声がかぶるので不明瞭になる)や、会議(発音の不明瞭な人がいる)の議事録作成に利用するのは少し難しいようです。
これは当然のことで、人が音声ファイルから文字起こしを行っても、満足いくような結果にするには、何度か聞き直す必要があるかと思いますので、使う対象(音声ファイル)を考えて利用すれば、結構使えるサービスではないかと思います。
まとめ
AIが音声ファイルをテキスト化
Speech to Text Demo サービスでは、音声ファイルから無料でテキスト化を行うことが可能です。
Speech to Text Demo について
- アラビア語、英語、スペイン語、フランス語、ブラジルポルトガル語、日本語、韓国語、ドイツ語、北京語の音声をテキストに変換できます。
- 音声ファイル対応フォーマットは、mp3、mpeg、wav、flac、opusです。
音声ファイル・テキスト化のやり方
- 「Voice Model」を「Japanese broadband model(16KHz)」に設定します。
- 話者が複数いる場合は、「Detect multiple speakers」をチェックする。
- 「Upload Audio File」をクリックして、mp3などの音声ファイルを選択し、アップロードする。
- あとは、タダ待つだけです。

コメント